

主从复制
后期或者大项目如果进一步优化 Redis,则使用主从复制,降低压力,提高效率。
概念
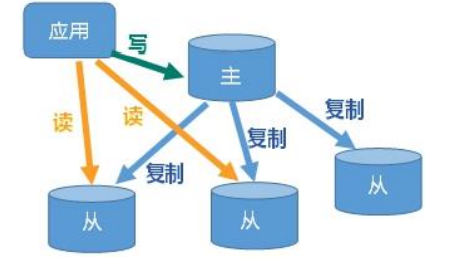
主从复制,是指将一台 Redis 服务器的数据,复制到其他的 Redis 服务器。前者称为主节点(master/leader),后者称为从节点(slave/follower);数据的复制是单向的,只能由主节点到从节点。Master 以写为主,Slave 以读为主。
默认情况下,每台 Redis 服务器都是主节点;且一个主节点可以有多个从节点(或没有从节点),但一个从节点只能有一个主节点。
主从复制的作用主要包括:
数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式
故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余
负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务 (即写 Redis 数据时应用连接主节点,读 Redis 数据时应用连接从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高 Redis 服务器的并发量
高可用基石:除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是 Redis 高可用的基础
一般来说,要将 Redis 运用于工程项目中,只使用一台 Redis 是万万不能的,原因如下:
从结构上,单个 Redis 服务器会发生单点故障,并且一台服务器需要处理所有的请求负载,压力较大
从容量上,单个 Redis 服务器内存容量有限,就算一台 Redis 服务器内存容量为 256G,也不能将所有内存用作 Redis 存储内存,一般来说,单台 Redis 最大使用内存不应该超过 20G
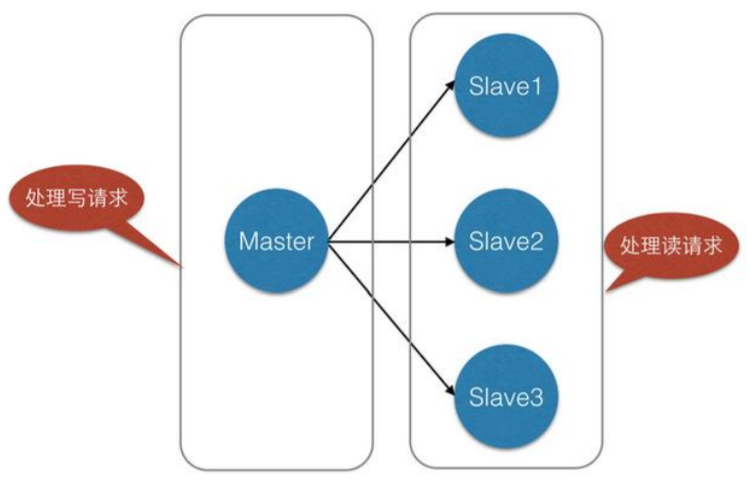
电商网站上的商品,一般都是一次上传,无数次浏览的,说专业点也就是「多读少写」。
对于这种场景,我们可以使如下这种架构:
环境配置
查看当前库的信息:info replication
127.0.0.1:6379> info replication
# Replication
role:master # 角色
connected_slaves:0 # 从机数量
master_failover_state:no-failover
master_replid:1a6933acf7ec9711bfa0a1848976676557e1e6a0
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
127.0.0.1:6379>因为没有多个服务器,就以本地开启 3 个端口,模拟 3 个服务
既然需要启动多个服务,就需要多个配置文件。每个配置文件对应修改以下信息:
- 端口号(port)
- pid文件名(pidfile)
- 日志文件名(logfile)
- rdb文件名(dbfilename)
拷贝多个 redis.conf 文件
端口分别是 6379、6380、6381,且每个文件开启 daemonize yes
[root@localhost ~]# cd /usr/local/bin/myredis
[root@localhost myredis]# ls
dump.rdb redis.conf
[root@localhost myredis]# cp redis.conf redis79.conf
[root@localhost myredis]# cp redis.conf redis80.conf
[root@localhost myredis]# cp redis.conf redis81.conf
[root@localhost myredis]# ls
dump.rdb redis79.conf redis80.conf redis81.conf redis.conf分别修改配置上面四点对应的配置,举例:


配置好分别启动 3 个不同端口服务
redis-server myredis/redis79.conf
redis-server myredis/redis80.conf
redis-server myredis/redis81.conf
配置三类
一主二从
主的文件(redis79.conf)
include /etc/redis.conf # 核心配置文件
pidfile /var/run/redis_6379.pid # 固定
port 6379 #端口
dbfilename dump6379.rdb # 持久化备份文件
daemonize yes
protected-mode no
dir "/myredis" # 备份文件路径,自定义二从的文件(redis80.conf、redis81.conf)
include /etc/redis.conf # 核心配置文件
pidfile /var/run/redis_6380.pid # 固定
port 6380 #端口
dbfilename dump6380.rdb # 持久化备份文件
daemonize yes
protected-mode no
dir "/myredis" # 备份文件路径,自定义
###################################################
include /etc/redis.conf # 核心配置文件
pidfile /var/run/redis_6381.pid # 固定
port 6381 #端口
dbfilename dump6381.rdb # 持久化备份文件
daemonize yes
protected-mode no
dir "/myredis" # 备份文件路径,自定义如果重新配置了文件内容,则需要重启 Redis 服务。
启动好 3 个不同端口服务后,我们再分别开启 Redis 连接
shredis-cli -p 6379 redis-cli -p 6380 redis-cli -p 6381通过
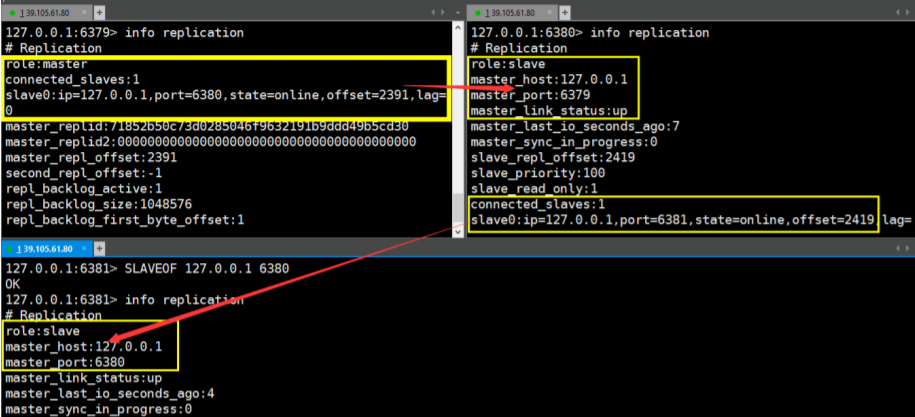
info replication指令查看信息bash127.0.0.1:6379> info replication可以发现,默认情况下,开启的每个 Redis 服务器都是主节点
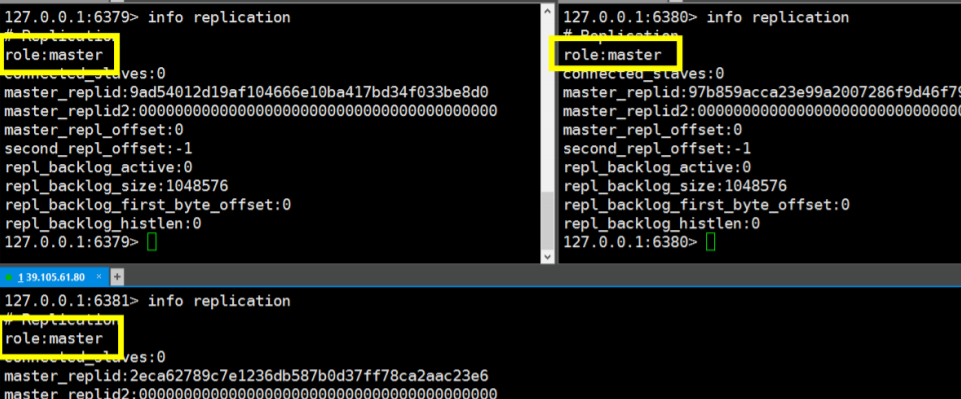
配置为一个 Master 和 两个 Slave(即一主二从)
6379 为主,6380、6381 为从,分别在 6380、6381 的 Redis 上执行如下指令:
shslaveof 127.0.0.1 6379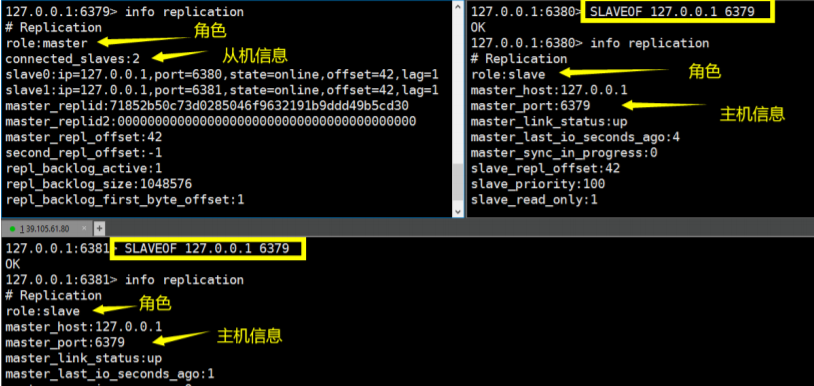
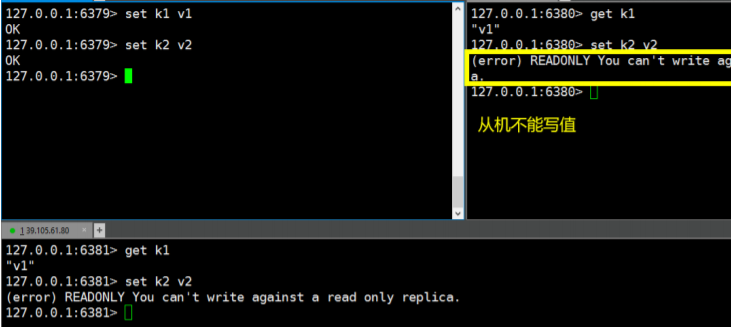
在主机设置值,在从机都可以取到,但是从机不能写值
我们这里是使用命令搭建,是「暂时的」,如果重启三个 Redis 服务,则又恢复到三主的地位
如果想配置「永久的」,则去配置里进行修改,找到
slaveof <ip> <port>指令进行配置:
使用规则
当主机断电宕机后,默认情况下从机的角色不会发生变化,集群中只是失去了写操作,当主机恢复以后,又会连接上从机恢复原状。
当从机断电宕机后,若不是使用配置文件配置的从机,再次启动后作为主机是无法获取之前主机的数据的,若此时重新配置称为从机,又可以获取到主机的所有数据。这里就要提到一个复制原理。
复制原理
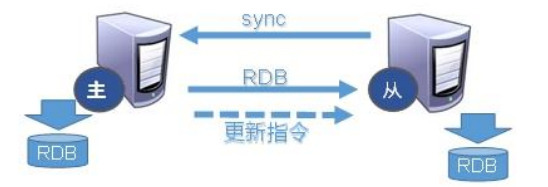
Slave 启动成功连接到 Master 后会发送一个 sync 命令
Master 接到命令,启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台进程执行完毕之后,Master 将传送整个数据文件到 Slave,并完成一次完全同步
全量复制:而 Slave 服务在接收到数据库文件数据后,将其存盘并加载到内存中
增量复制:Master 继续将新的所有收集到的修改命令依次传给 Slave,完成同步
但是只要是重新连接 Master,一次完全同步(全量复制)将被自动执行
有两种方式可以产生新的主机:看下文「反客为主」
薪火相传
上一个 Slave 可以是下一个 Slave 和 Master,Slave 同样可以接收其他 Slaves 的连接和同步请求,那么该 Slave 作为了链条中下一个的 Master,可以有效减轻 Master 的写压力,去中心化降低风险。
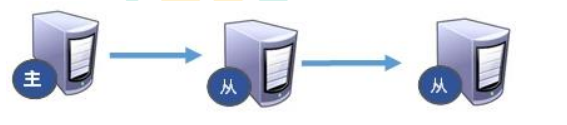
在一个从机用 slaveof <ip> <port> 指令连接另一个从机。
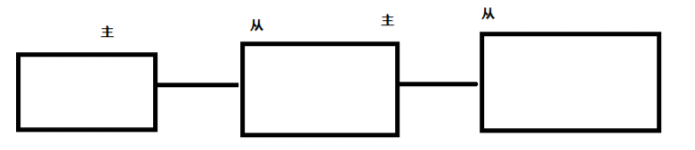
或者在配置文件里找到 slaveof <ip> <port> 指令进行配置。
反客为主
当一个 master 宕机后,后面的 slave 可以立刻升为 master,其后面的 slave 不用做任何修改。
有两种方式可以产生新的主机:
- 从机手动执行命令
slaveof no one,这样执行以后从机会独立出来成为一个主机 - 使用哨兵模式(自动选举)
哨兵模式
什么是哨兵模式
主从切换技术的方法是:当主服务器宕机后,需要手动把一台从服务器切换为主服务器,这就需要人工干预,费事费力,还会造成一段时间内服务不可用。这不是一种推荐的方式,更多时候,我们优先考虑哨兵模式。Redis 从 2.8 开始正式提供了 Sentinel(哨兵)架构来解决这个问题。
反客为主的自动版,能够后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库。
哨兵模式是一种特殊的模式,首先 Redis 提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它会独立运行。其原理是 哨兵通过发送命令,等待 Redis 服务器响应,从而监控运行的多个 Redis 实例。
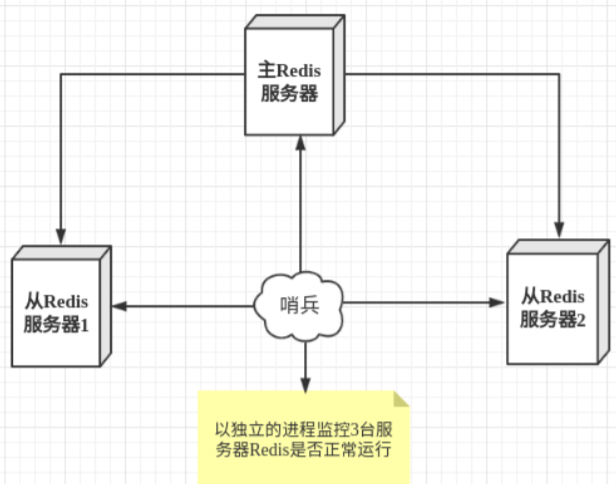
这里的哨兵有两个作用:
- 通过发送
Info Replication命令,让 Redis 服务器返回监控其运行状态,包括主服务器和从服务器 - 当哨兵监测到 Master 宕机,会自动将 Slave 切换成 Master,然后通过 发布订阅模式 通知其他的从服务器,修改配置文件,让它们切换主机
然而一个哨兵进程对 Redis 服务器进行监控,可能会出现问题,为此,我们可以使用多个哨兵进行监控。各个哨兵之间还会进行监控,这样就形成了多哨兵模式。
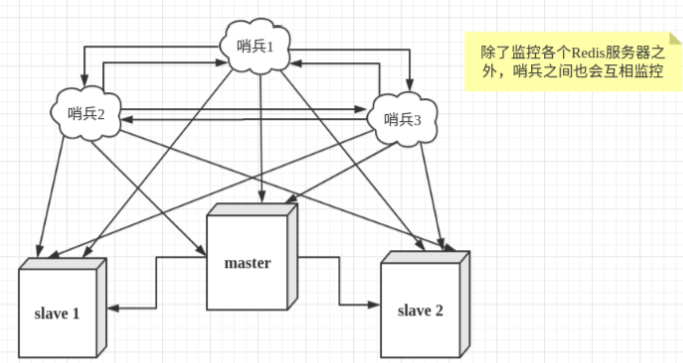
假设主服务器宕机,哨兵 1 先检测到这个结果,系统并不会马上进行 failover(故障转移)过程,仅仅是哨兵 1 主观的认为主服务器不可用,这个现象成为 主观下线。当后面的哨兵也检测到主服务器不可用,并且数量达到一定值时,那么哨兵之间就会进行一次投票,投票的结果由一个哨兵发起,进行 failover(故障转移)操作。切换成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机,这个过程称为 客观下线。
哨兵监控主机命令:sentinel monitor <master-name> <ip> <port> <count>。
监控主节点的名字(自定义一个名字)、IP 和端口,最后一个 count 的意思是有几台 Sentinel 发现有问题,就会发生故障转移,例如配置为 2,代表至少有 2 个 Sentinel 节点认为主节点不可达,那么这个不可达的判定才是客观的。对于设置的越小,那么达到下线的条件越宽松,反之越严格。一般建议将其设置为 Sentinel 节点的一半加 1,count 不得大于 Sentinel 的个数。
集群脑裂
脑裂,也就是说,某个 Master 所在机器突然脱离了正常的网络,跟其它 Slave 机器不能连接,但是实际上 Master 还运行着。
造成的问题
此时哨兵可能就会认为 Master 宕机了,然后开始选举,让其它 Slave 切换成 Master。这时候集群里就会有 2 个 Master,也就是所谓的脑裂。此时虽然某个 Slave 被切换成了 Master,但是可能 Client 还没来得及切换成新的 Master,还继续写向旧的 Master,这样数据可能就丢失了。因此旧 Master 再次恢复的时候,会被作为一个 Slave 挂到新的 Master 上去,自己的数据会被清空,重新从新的 Master 复制数据。
解决
在配置文件添加(模板):
min-slaves-to-write 1
min-slaves-max-lag 10要求至少有 1 个 Slave,数据复制和同步的延迟不能超过 10 秒
如果说一旦所有的 Slave,数据复制和同步的延迟都超过了 10 秒钟,那么这个时候,Master 就不会再接收任何请求了
上面两个配置可以减少 异步复制 和 脑裂导致 的数据丢失。
原理:正常的 Slave 从 Master 复制数据,除了刚开始启动时需要全部复制,其他时候都是复制新的数据(增量复制),耗时少,一旦出现复制时间很长,则代表该 Slave 是刚启动的,非常有可能是旧的 Master 宕机重新启动,所以通过复制超时时间来判断是否是异步复制或者脑裂导致。
异步复制导致的数据丢失
在异步复制的过程当中,通过 min-slaves-max-lag 这个配置,就可以确保的说,一旦 Slave 复制数据和 ack 延迟时间太长,就认为可能 Master 宕机后损失的数据太多了,那么就拒绝写请求,这样就可以把 Master 宕机时由于部分数据未同步到 Slave 导致的数据丢失降低到可控范围内。
集群脑裂导致的数据丢失
集群脑裂因为 Client 还没来得及切换成新的 Master,还继续写向旧的 Master,这样数据可能就丢失了,通过 min-slaves-to-write 确保必须是有多少个从节点连接,并且延迟时间小于 min-slaves-max-lag 多少秒。
配置测试
调整结构,6379 带着 80、81
自定义的 /myredis 目录下新建 sentinel.conf 文件,名字千万不要错
配置哨兵,填写内容
sentinel monitor 被监控主机名字 127.0.0.1 6379 1例如: ```sh sentinel monitor mymaster 127.0.0.1 6379 1 ``` 上面最后一个数字 1,表示主机挂掉后 Slave 投票看让谁接替成为主机,得票数多少后成为主机,这里的例子是 1 票。
启动哨兵
shredis-sentinel myredis/sentinel.conf
上述目录依照各自的实际情况配置,可能目录不同
成功启动哨兵模式:
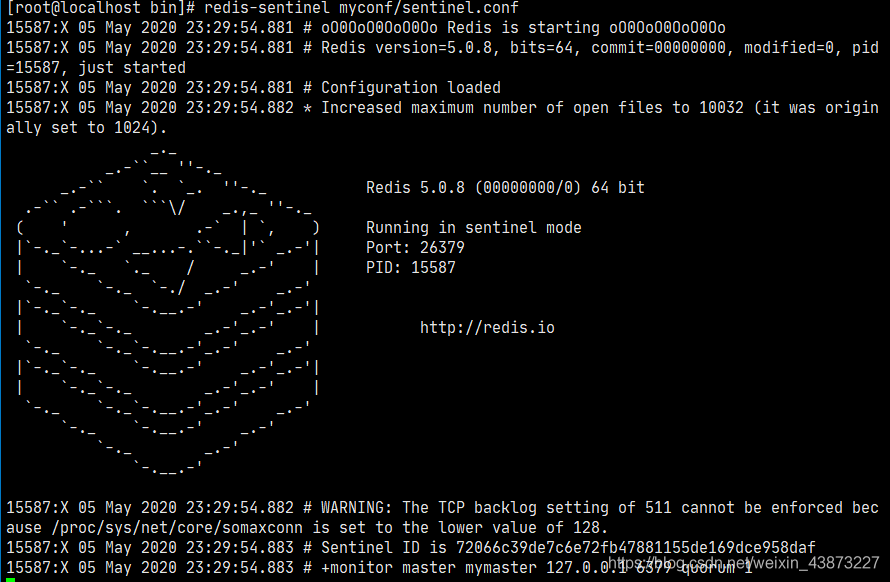
此时哨兵监视着我们的主机 6379,当我们断开主机后:
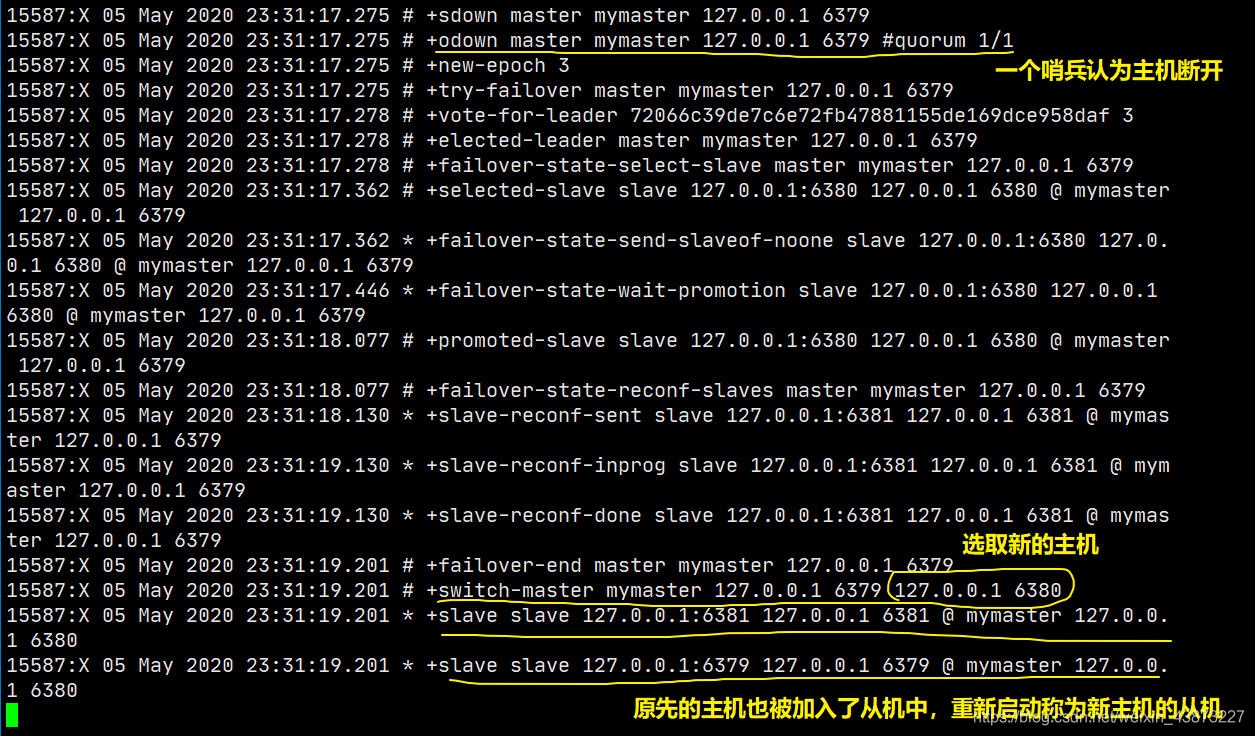
哪个从机会被选举为主机呢?根据优先级别:slave-priority,这个指令需要去每个从机的配置文件进行配置,默认都是 100。
建议每个从机都配置不同的 slave-priority,这样可以避免复制延时。
值越小优先级越高。
复制延时
由于所有的写操作都是先在 Master 上操作,然后同步更新到 Slave 上,所以从 Master 同步到 Slave 机器有一定的延迟,当系统很繁忙的时候,延迟问题会更加严重,Slave 机器数量的增加也会使这个问题更加严重。
哨兵模式的优缺点
优点:
- 哨兵集群,基于主从复制模式,所有主从复制的优点,它都有
- 主从可以切换,故障可以转移,系统的可用性更好
- 哨兵模式是主从模式的升级,手动到自动,更加健壮
缺点:
- Redis 不好在线扩容,集群容量一旦达到上限,在线扩容就十分麻烦
- 实现哨兵模式的配置其实是很麻烦的,里面有很多配置项
哨兵模式的全部配置
完整的哨兵模式配置文件 sentinel.conf
# Example sentinel.conf
# 哨兵 sentinel 实例运行的端口 默认 26379
port 26379
# 哨兵 sentinel 的工作目录
dir /tmp
# 哨兵 sentinel 监控的 redis 主节点的 ip port
# master-name:自定义命名的主节点名字 只能由字母 A-z、数字 0-9 、这三个字符 ".-_" 组成。
# quorum:当这些 quorum 个数 sentinel 哨兵认为 Master 主节点失联 那么这时客观上认为主节点失联了
# sentinel monitor <master-name> <ip> <redis-port> <quorum>
sentinel monitor mymaster 127.0.0.1 6379 1
# 当在 Redis 实例中开启了 requirepass foobared 授权密码 这样所有连接 Redis 实例的客户端都要提供密码
# 设置哨兵 sentinel 连接主从的密码 注意必须为主从设置一样的验证密码
# sentinel auth-pass <master-name> <password>
sentinel auth-pass mymaster MySUPER--secret-0123passw0rd
# 指定多少毫秒之后 主节点没有应答哨兵 sentinel 此时 哨兵主观上认为主节点下线 默认 30 秒
# sentinel down-after-milliseconds <master-name> <milliseconds>
sentinel down-after-milliseconds mymaster 30000
# 这个配置项指定了在发生 failover 主备切换时最多可以有多少个 Slave 同时对新的 Master 进行同步,
# 这个数字越小,完成 failover 所需的时间就越长,
# 但是如果这个数字越大,就意味着越 多的 Slave 因为 replication 而不可用。
# 可以通过将这个值设为 1 来保证每次只有一个 Slave 处于不能处理命令请求的状态。
# sentinel parallel-syncs <master-name> <numslaves>
sentinel parallel-syncs mymaster 1
# 故障转移的超时时间 failover-timeout 可以用在以下这些方面:
#1. 同一个 sentinel 对同一个 Master 两次 failover 之间的间隔时间。
#2. 当一个 Slave 从一个错误的 Master 那里同步数据开始计算时间。直到 Slave 被纠正为向正确的 Master 那里同步数据时。
#3. 当想要取消一个正在进行的 failover 所需要的时间。
#4. 当进行 failover 时,配置所有 Slaves 指向新的 Master 所需的最大时间。不过,即使过了这个超时,Slaves 依然会被正确配置为指向Master,但是就不按 parallel-syncs 所配置的规则来了
# 默认三分钟
# sentinel failover-timeout <master-name> <milliseconds>
sentinel failover-timeout mymaster 180000
# SCRIPTS EXECUTION
# 配置当某一事件发生时所需要执行的脚本,可以通过脚本来通知管理员,例如当系统运行不正常时发邮件通知相关人员。
# 对于脚本的运行结果有以下规则:
# 若脚本执行后返回 1,那么该脚本稍后将会被再次执行,重复次数目前默认为 10
# 若脚本执行后返回 2,或者比 2 更高的一个返回值,脚本将不会重复执行。
# 如果脚本在执行过程中由于收到系统中断信号被终止了,则同返回值为 1 时的行为相同。
# 一个脚本的最大执行时间为 60s,如果超过这个时间,脚本将会被一个 SIGKILL 信号终止,之后重新执行。
# 通知型脚本:当 sentinel 有任何警告级别的事件发生时(比如说 Redis 实例的主观失效和客观失效等等),将会去调用这个脚本,
# 这时这个脚本应该通过邮件,SMS 等方式去通知系统管理员关于系统不正常运行的信息。调用该脚本时,将传给脚本两个参数,
# 一个是事件的类型,
# 一个是事件的描述。
# 如果 sentinel.conf 配置文件中配置了这个脚本路径,那么必须保证这个脚本存在于这个路径,并且是可执行的,否则 sentinel 无法正常启动成功。
# 通知脚本
# sentinel notification-script <master-name> <script-path>
sentinel notification-script mymaster /var/redis/notify.sh
# 客户端重新配置主节点参数脚本
# 当一个 Master 由于 failover 而发生改变时,这个脚本将会被调用,通知相关的客户端关于 Master 地址已经发生改变的信息。
# 以下参数将会在调用脚本时传给脚本:
# <master-name> <role> <state> <from-ip> <from-port> <to-ip> <to-port>
# 目前 <state> 总是「failover」,
# <role> 是「leader」或者「observer」中的一个。
# 参数 from-ip, from-port, to-ip, to-port 是用来和旧的 Master 和新的 Master(即旧的 Slave)通信的
# 这个脚本应该是通用的,能被多次调用,不是针对性的。
# sentinel client-reconfig-script <master-name> <script-path>
sentinel client-reconfig-script mymaster /var/redis/reconfig.sh